Here is another performance improvement that just landed on master.
Background
It was brought to our attention that the performance of saving documents to ODF spreadsheet format had been degrading quite noticeably. This was especially true when the document contained lots of what we call rich text cells. Rich text cells are those cells that contain text with mixed format spans, or text that consists of multiple lines. These cells are handled differently from simple strings internally, and have slightly more overhead than the simple string counterparts. Because of this, saving a document full of such texts was always slower than saving one with just numbers and simple strings.
However, even with this unavoidable overhead, the performance of saving rich text cells was clearly going in the wrong direction. Therefore it was time to act.
Long story short, after many days of code reading and writing, I brought it to a state where I can share some numbers.
Measuring export performance
I measured the performance of exporting rich text cells in the following steps.
Create a new spreadsheet document.
Type in cell A1 3 lines of ‘libreoffice’. Here, you can hit Ctrl-Enter to move to the next line within the same cell.
Copy A1, select A1:N1000 and paste, to replicate the content of A1 to all cells in the range.
Save the document as ODF spreadsheet document, and measure its duration.
Results
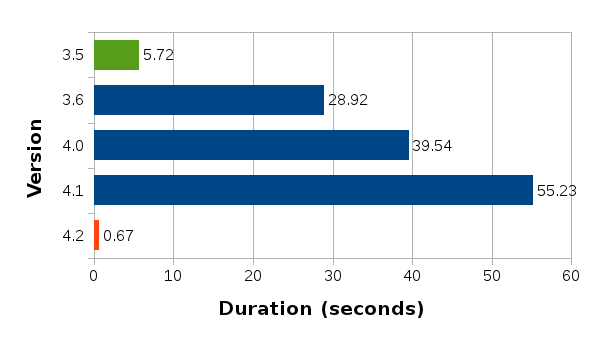
I performed the above measurement with 3.5, 3.6, 4.0, 4.1, and the latest master (slated to become 4.2) builds, and these are the numbers.
It is clear from this chart that the performance started to suffer first in version 3.6, then gradually worsened over 4.0 and 4.1. The good news is that we have managed to bring the number back down in the master build, even lower than that of 3.5 which I used as the point of reference. Not just slightly lower, but much, much lower.
I don’t know about you, but I’m quite happy with this result.
This week I have finally finished implementing a true shared formula framework in Calc core which allows Calc to share token array instances between adjacent formula cells if they contain identical set of formula tokens. Since one of the major benefits of sharing formula token arrays is reduced memory footprint, I decided to measure the trend in Calc’s memory usages since 4.0 all the way up to the latest master, to see how much impact this shared formula work has made in Calc’s overall memory footprint.
Test document
Here is the test document I used to measure Calc’s memory usage
This ODF spreadsheet document contains 100000 rows of cells in 4 columns of which 399999 are formula cells. Column A contains a series of integers that grow linearly down the column. Here, only the first cell (A1) is a numeric cell while the rest are all formula cells that reference their respective immediate upper cell. Cells in Column B all reference their immediate left in Column A, cells in Column C all reference their immediate left in Column B, and so on. References used in this document are all relative references; no absolute references are used.
Tested builds
I’ve tested a total of 4 builds. One is the 4.0.1 build packaged for openSUSE 11.4 (x64) from the openSUSE repository, one is the 4.0.6 build built from the 4.0 branch, one is the 4.1.1 build built from the 4.1 branch, and the last one is the latest from the master branch. With the exception of the packaged 4.0.1 build, all builds are built locally on my machine running openSUSE 11.4 (x64). Also on the master build, I’ve tested memory usage both with and without shared formulas.
Results
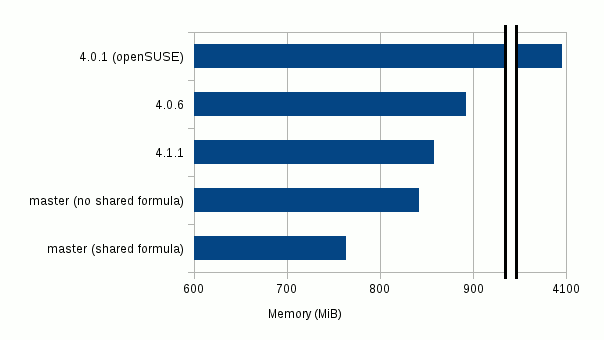
In each tested build, the memory usage was measured by directly opening the test document from the command line and recording the virtual memory usage in GNOME system monitor. After the document was loaded, I allowed for the virtual memory reading to stabilize by waiting several seconds before recording the number. The results are presented graphically in the following chart.
The following table shows the actual numbers recorded.
Build
Virtual memory
4.0.1 (packaged by openSUSE)
4.0 GiB
4.0.6
892.1 MiB
4.1.1
858.4 MiB
master (no shared formula)
842.2 MiB
master (shared formula)
763.9 MiB
Additionally, I’ve also measured the number of token array instances between the two master builds (one with shared formula and one without), and the build without shared formula created 399999 token array instances (exactly 4 x 100000 – 1) upon file load, whereas the build with shared formula created only 4 token array instances. This likely accounts for the difference of 78.3 MiB in virtual memory usage between the two builds.
Effect of cell storage rework
One thing worth noting here is that, even without shared formulas, the numbers clearly show a steady decline of Calc’s memory usage from 4.0 to 4.1, and to the current master. While we can’t clearly infer from these numbers alone what caused the memory usage to shrink, I can say with reasonable confidence that the cell storage rework we did during the same period is a significant factor in such memory footprint shrinkage. I won’t go into the details of the cell storage rework here; I’ll reserve that topic for another blog post.
Oh by the way, I have absolutely no idea why the 4.0.1 build packaged from the openSUSE repository shows such high memory usage. To me this looks more like an anomaly, indicative of earlier memory leaks we had later fixed, different custom allocator that only the distro packaged version uses that favors large up-front memory allocation, or anything else I haven’t thought of. Either way, I’m not counting this as something that resulted from any of our improvements we did in Calc core.
Last week was SUSE’s Hack Week – an event my employer does periodically to allow us – hard working engineers – to go wild with our wildest ideas and execute them in one week. Just like what I did at my last Hack Week event, I decided to work on integration of Orcus library into LibreOffice once again, to pick up on what I’d left off from my previous integration work.
Integration bits
Prior to Hack Week, orcus was already partially integrated; it was used to provide the backend functionality for Calc’s XML Source feature, and experimental support for Gnumeric file import. The XML Source side was pretty well integrated, but the normal file import side was only partially integrated. Lots of essential pieces were still missing, the largest of which were
support for multiple filters from a single external filter provider source (such as orcus),
progress indicator in the status bar, and
proper type detection by analyzing file content rather than its extension (which we call “deep detection”).
In short, I was able to complete the first two pieces during Hack Week, while the last item still has yet to be worked on. Aside from this, there are still more minor pieces missing, but perhaps I can work on the remaining bits during the next Hack Week.
Enabling orcus in your build
If you have a recent enough build from the master branch of the LibreOffice repository, you can enable imports via orcus library by
checking the Enable experimental features box in the Options dialog, and
setting the environment variable LIBO_USE_ORCUS to YES before launching Calc.
This will overwrite the stock import filters for ODS, XLSX and CSV. At present, orcus only performs file extension based detection rather than content based one, so be mindful of this when you try this on your machine. To go back to the current import filters, simply disable experimental features, or unset the environment variable.
Note that I’ve added this bits to showcase a preview of what orcus can potentially do as a future import filter framework. As such, never use this in production if you want stable file loading experience, or don’t file bugs against this. We are not ready for that yet. Orcus filters are still missing lots and lots of features.
Also note that, while in theory you could enable orcus with the Windows build, the performance of orcus on Windows may not be that impressive; in fact, in some cases slower than the current filters. That is because orcus relies on strtod and strtol system calls to convert string numbers into numeric values, and their implementation depend on the platform. And the performance of MSVC’s strtod implementation is known to be suboptimal compared to those of gcc and clang on Linux. I’m very much aware of this, and will work on addressing this at a later time.
Performance comparison
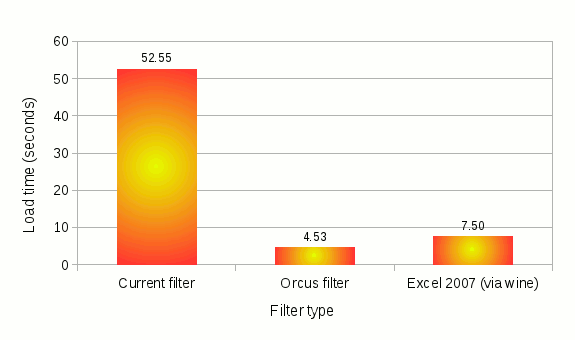
This is perhaps the most interesting part. I wanted to do a quick performance comparison and see how this orcus filter stands up against the current filter. Given the orcus filter is still only capable of importing raw cell values and not any other features or properties (not even cell formats), I’ve used this test file which only consists of raw text and numeric values in a 8-by-300000 range, to measure the load times that are as fair and representative as I could make them. Here is the result on my machine running openSUSE 11.4:
The current filter, which has undergone its set of performance optimizations on raw cell values, still spends upwards of 50 seconds. Given that it used to take minutes to load this file, it’s still an improvement.
The orcus filter, on the other hand, combined with the heavily optimized load handler in Calc core that I put in place during Hack Week, can load the same file in 4.5 seconds. I would say that is pretty impressive.
I also measured the load time on the same file using Excel 2007, on the same machine running on top of wine, and the result was 7.5 seconds. While running an Windows app via wine emulation layer may incur some performance cost, this page suggests that it should not be noticeable, if any. And my own experience of running various versions of Excel via wine backs up that argument. So this number should be fairly representative of Excel’s native performance on the same hardware.
Considering that my ultimate goal with orcus is to beat Excel on performance on loading its own files (or at least not be slower than Excel), I would say we are making good progress toward that goal.
That’s all for today. Thank you, ladies and gentlemen.
Ok. I’m actually a bit late on this announcement since 10 days have already passed since the actual release of 0.7.1. Anyhow, I will hereby announce that version 0.7.1 of Multi-Dimensional Data Structure (mdds) is out, which contains several critical bug fixes over the previous 0.7.0 release. You can download the source package from here:
0.7.1 fixes several bugs in the set_empty() method of multi_type_vector. In the previous versions, the set_empty() method would fail to merge two adjacent empty blocks into a single block, which violated the basic requirement of multi_type_vector that it never allows two adjacent blocks of identical type. This caused other parts of multi_type_vector to fail as a result.
There are no API-incompatible changes since version 0.7.0. I highly recommend you update to 0.7.1 if you make heavy use of multi_type_vector and still use any versions older than 0.7.1.
I had the pleasure to visit the Open Source Conference (OSC) 2013 in Tokyo, which took place at Meisei University located on the outskirt of Tokyo. They do organize these OSC’s on a very frequent basis throughout the year, being hosted at various cities across Japan.
Background
Normally I don’t travel to Japan just to visit OSC mainly because of the distance; being located in the East Coast of the United States, it’s a big hassle to fly to Japan, not to mention the cost. Despite this, I wanted to visit this particular OSC primarily for two reasons.
I had received an email from someone from the Japan OSS Promotion Forum that I had been nominated for the 2013 OSS Contributor’s Award, and he asked me whether I could participate the award ceremony which would take place during the conference.
The LibreOffice Japanese team had organized a separate track just for LibreOffice related talks, and I wanted to come and see face-to-face the people who are involved in our project in Japan in various capacities, and learn the latest on what’s going in the Japanese community.
There was one difficulty, however. Because I only had one week to arrange the travel (I got the email only a week before the scheduled ceremony date) I could not guarantee my arrival until the very last minute. Luckily everything went smoothly and I was able to book my flight and reserve my hotel despite the short notice.
Meisei University
Tama Monorail that takes you to the venue.
This is actually my second time coming to this event. My first visit was in 2010. I was planning my trip to Tokyo to attend a different, work-related meeting. Then I learned about OSC Tokyo 2010 which was scheduled only one day after the meeting was scheduled to end, so I decided to extend my stay in Tokyo for just one more day to visit OSC. OSC 2010 was also held at Meisei University, so at least I didn’t have to research on how to get the conference venue this time.
Once on campus, there were signs all around the place that would take you to the building where the conference was held. Outside the venue, the campus was pretty quiet, and I didn’t see very many students.
Booths
No conferences are complete without booths. Various projects set up booths to greet the visitors, to distribute fliers and CD/DVD’s, and to inform them of what’s new in the projects. Volunteers from the LibreOffice Japanese team manned our booth throughout the conference. We distributed version 4.0 feature fliers, installer CD’s, T-shirts, stickers and flags.
LibreOffice booth and volunteers from the Japanese team. LibreOffice booth, Shinji Enoki (Enoki-san) answering questions.
Also present was the openSUSE project booth. Fuminobu Takeyama was single-handedly manning the booth when I dropped by on Friday. He is a volunteer in the openSUSE project who also manages several packages for Japanese locales. We briefly talked about some issues with Japanese input method in LibreOffice, and how some folks work around it by forcing the GTK VCL backend even if LibreOffice is launched in the KDE environment (because the input method code in the GTK VCL backend is more reliable than that in the KDE VCL). He said he is very much hoping to someday find time to look into LibreOffice code, to solve various Japanese-related issues that are still outstanding in the latest release.
Bunch of Geeko’s piled up at the openSUSE booth. Sitting next to them are Japan’s Firefox mascot Foku-Suke. Fuminobu Takeyama looking friendly at the openSUSE booth.
OSS Contributor’s Award
Me receiving a Contributor’s Award
The ceremony for the OSS Contributor’s Awards was held on Friday evening. The OSS Contributor’s Awards are given to
“those who have created or managed an influential development project and to developers who have played an important role in a global project or those who have contributed to the promotion of related activities.” (quoted from this slide)
The candidates are nominated publicly, and the winners are selected by the Awards Committee. They select four winners and nine incentive award winners each year, and I was fortunate enough to have been selected as one of the four award winners this year.
My short talk after the ceremony, outlining my current activities etc.
The ceremony was held in a separate, moderately-sized lecture room right next to the booth areas, and was very well attended. Out of four winners, two of us were present to receive the awards: Tetsuo Handa and myself. We each gave a brief 10-minutes talk afterward, outlining our current activities and our future plans.
Handa-san is a well known Linux kernel hacker and he is leading the development of a kernel security module known as TOMOYO Linux. We briefly chatted after the ceremony, and he hinted that he may get a chance to hack on LibreOffice in the distant future (and I encouraged him!) So, let’s keep his name in the back of our mind, and hope we can see him in our project someday. ;-)
You can find two press articles on this here and here. The official announcement from the OSS Forum is here.
LibreOffice mini-Conference
I spent the second day of the conference mostly in the LibreOffice mini-Conference track. According to Naruhiko-san, this is our first ever track dedicated to LibreOffice (and hopefully won’t be the last) held in Japan. We were able to rent a pretty large lecture room for the whole day to host this mini-Conference. Despite the large size, the room was moderately attended.
The first talk was by Miyoshi Ohmori, and his talk was about the company-wide migration from OpenOffice.org to LibreOffice at NTT Comware. In his talk, he shared the challenges he faced during the migration and ways to solve them. Miyoshi Ohmori talks about migration from OpenOffice.org to LibreOffice.
Next up was a talk by Shinji Enoki covering new features in LibreOffice 4.0. He covered all aspects of new features in 4.0, from Firefox Personas support, to Calc’s import filter performance improvement, and everything in-between. His talk was followed by Naruhiko Ogasawara who shared his experience with his trip to the 2nd LibreOffice Conference in Berlin, how he decided to join the LibreOffice community, and how he decided to submit paper for the conference and eventually travel there. During his talk, Ogasawara-san played the video message from Italo that was created specifically for the Japanese audience. Shinji Enoki talks about what’s new in LibreOffice 4.0. Naruhiko Ogasawara talks about his trip to the 2nd LibreOffice Conference in Berlin. Italo’s video message with Japanese caption.
If you thought Enoki-san and Ogasawara-san looked familiar, it was because they came to the Berlin conference to co-present a talk on the topic of the non-English locale communities. The slide for their talk during the Berlin conference is found here. Enoki-san later traveled to Prague with me and the rest of SUSE’ers, to meet with Petr Mladek to learn more about the current QA activities. (Petr couldn’t make it to Berlin due to illness). Anyway, back to the mini-Conf…
The last talk before the lunch break was by Masaki Tamakoshi. In his talk, he presented a good extension to use to add AutoCAD-like functionality to Draw to make Draw easier and more familiar to use for former (or current) AutoCAD users. He also talked about how to convert AutoCAD’s proprietary dwg files to make them loadable into Draw, and how to create playable animation files from Impress slides, using external tools. Masaki Tamakoshi talks about extension that adds AutoCAD-like functionality to Draw.
Jun Meguro discusses how to make professional use of Draw.
After the lunch break, Jun Meguro kickstarted the afternoon session with his talk on how to make effective use of Draw to create professional posters. His organization – City of Aizuwakamatsu – is in fact one of the first organizations in Japan that made a large scale adoption of OpenOffice.org when such a move was still not very common, and instantly became the poster child of OpenOffice.org adoption. They had later moved on to LibreOffice, and Meguro-san continues to contribute to the LibreOffice project as a member of the Japanese language team.
In his talk, he emphasized the usefulness of Draw – the application that may not have received the attention and praise it deserves, and how Draw can be used to create professional posters and fliers without purchasing expensive and proprietary alternatives. He also hinted during his talk that, these days, they can send ODF documents to other local government offices without first converting them to MS Office or PDF formats. This was first revealed when he accidentally sent off a native Draw document (odg) without converting it to PDF, and later received a phone call from the recipient of the document to discuss about the details of the drawing! Although this is an isolated incident, an anecdote like this may suggest that the actual rate of ODF adoption may well be higher than we may have expected.
Masahisa Kamataki talks about cloud services that support ODF.
In the next talk, Masahisa Kamataki talked about how to make use of FLOSS office suites such as LibreOffice, combined with non-FLOSS but free as in beer cloud services such as SkyDrive and Google Drive to reduce operation costs. He mentioned that all of this was made possible thanks to the international standard ODF which many major cloud services also support these days. He also demonstrated the level of ODF compatibilities between these cloud services.
Ikuya Awashiro conducts his presentation via Impress Remote.
Next up was Ikuya Awashiro. He talked about the specifics of LibreOffice Japanese localization effort. As someone who coordinates the Japanese translation of LibreOffice UI strings, he knows the in’s and out’s of LibreOffice translation which he covered extensively in his talk. He also talked about the detailed history of the translation in this code base, dating back to the old OpenOffice.org days, and how he learned what not to do in order to successfully coordinate the current community-based translation effort in our project.
I should also mention that, of all the presenters we had during this track (including myself), he was the only presenter who used the Impress Remote feature!
Makoto Takizawa talks about ODF interoperability between various ODF producers, with live demos using SkyDrive and Calligra.
Makoto Takizawa concluded the afternoon session with his ODF PlugFest talk which also happened to be the very last talk in the whole LibreOffice track.
He started off his talk with the basics of ODF, including its standardization history, and went on to talk about various ODF-supporting applications and how each of these apps fares on interoperability test. During his talk he noted that, although in theory the use of ODF ensures seamless interoperability between different supporting applications, in reality there are still some nasty corner cases where different ODF producers interpret ODF differently.
Toward the end of his talk, he performed a live ODF spreadsheet scenario test using Calligra, Gnumeric, SkyDrive and LibreOffice, to test in real life the level of ODF conformance in these spreadsheet applications. In this particular scenario, Calligra, Gnumeric and SkyDrive actually scored higher than LibreOffice. He concluded his talk by pointing out the importance of the ODF user community assessing the conformance level of each ODF-supporting application, and actively giving feedback to the developer community to improve ODF interoperability between the supporting applications.
Lastly, while I was not officially on the list of speakers in this track, I managed to squeeze my talk during the lunch break, to briefly talk about various random development topics. Please refer to my earlier post to get a hold of the slide for my talk. Unfortunately I had to cut it short to give people enough time to eat lunch, but it sort of worked out since I didn’t have much time to prepare my talk to begin with! ;-)
All in all, I believe this was a quite successful LibreOffice track. We were able to see each other face-to-face which is not very easy to do given how widespread we are geographically. That is true even for those inside Japan, and more so for me. It was unfortunate that Takeshi Abe couldn’t make it for this event. Perhaps we should plan another conference during OSC Okinawa so that we get to see him again. LibreOffice Japanese language team photo. LibreOffice 4.0 launch party photo.
Conclusion
This was actually my very first time to participate in OSC Japan as a speaker, and mingle with so many people from various sectors of the Japanese market. I spoke to quite a lot of people in various capacities during the conference, and I was pleasantly surprised with the level of interest that they have toward LibreOffice. Various local governments are aggressively considering a switch to LibreOffice, with Aizuwakamatsu City and JA Fukuoka leading the way. Though the uptake of LibreOffice among Japanese corporations are still slow, Sumitomo Electric has recently announced their adoption of LibreOffice, so others who are still hesitating to switch may eventually follow suit. I also chatted with someone from a local school district working very hard to realize a district-wide adoption of LibreOffice, which suggests that people in the education sector also see value in adopting LibreOffice.
On the other side of the fence, however, we have yet to attract a healthy dose of developers toward LibreOffice from the Japanese developer community. It is my impression that Japan has a sizable Linux kernel developer community, and in fact, many of the participants at OSC Tokyo were kernel hackers. So, whatever reason they may have for not participating in the LibreOffice development, it’s not because of lack of talents and expertize; they are there, contributing to other projects. At the same time, I also saw lots of interest in hacking on LibreOffice from various people. So, the interest is there; what they just need is a means and justification to work on LibreOffice.
While chatting with Ogawa-san from Ashisuto, who provides paid support for LibreOffice, it is apparent that we are not very far from seeing companies emerging who are very eager to find developers to work on LibreOffice. It is therefore my hope that, by increasing the level of LibreOffice adoption amongst users, the level of interest in participating the development of LibreOffice among support vendors will increase proportionally as a result. And my own impression from participating in OSC Tokyo fills me with optimism in this regard.
All changes that went into this version since 0.6.1 are related to multi_type_vector. The highlights of the changes are:
setter methods (set, set_empty, insert, and insert_empty) now return an iterator that references the block where the values are set or inserted,
each of the above-referenced methods now have a variant that takes a position hint iterator for faster insertion, and
several critical bug fixes.
There are no API-incompatible changes since 0.6.1. If you currently use version 0.6.1 and use multi_type_vector, you should upgrade to 0.7.0 as it contains several important bug fixes.
The first one is the brief talk I did after the OSS Contributor Award ceremony on Friday.
This is saved as a hybrid PDF; you can view it in your regular PDF viewer (such as Evince and Adobe PDF viewer), or you can open it in Impress to edit it as a normal Impress document. Use this one in case you need it as a pure Impress document.
And the second one is for the talk I did during the LibreOffice mini-Conference on Saturday.
Like the 1st one, this one is also a hybrid PDF. The regular odp version is available here.
I will write more about OSC Tokyo and especially about the LibreOffice mini-Conference in a separate blog. Stay tuned.
I stumbled across this today entirely by accident, and I felt I had to write about it. What I’m about to tell you may or may not help you, but if you are interested, read on.
First, the disclaimer. I mainly use freedesktop.org’s bugzilla. And I will base my story on their bugzilla. If you use another bugzilla installation this may or may not apply to you since each site can add its own customization to it.
Named tags in Bugzilla
First, I need to explain what named tags in Bugzilla are, and how they work.
You may not have noticed this, but in Bugzilla, you can add your own custom tags to each bug report. To add a new tag to a bug report, scroll down to the bottom of the bug report to find the footer area which shows up in pretty much every page in bugzilla. It should look like this:
If you haven’t added any named tag to any bug report before, you won’t see any pre-selectable list of named tags in the list box on the left. Just type in a new tag in the tag box in the center, and click Commit to add it to the bug. If you are already in a bug report, the ID of that bug should be pre-filled in the bug number box (as in the screenshot). For now, I’ll add a new tag named “come back later” and click Commit.
You’ll see a page like this when you commit. When you click on that link labeled “come back later”, you’ll get to the list of all bugs that have that tag. Pretty easy, isn’t it?
Note that named tags are yours and yours only. They are visible only to you, and usable by nobody but you. It’s entirely private. When you add a tag to a bug report, it won’t send notification to whoever is watching that particular bug (unlike CC or whiteboard). And someone else may use the same tag in his or her account, and that won’t interfere with yours. But, since named tags are associated with your account, you need to have an account, or else named tags won’t be available.
Bugzilla Add-on for Firefox
Now, most of us spend the majority of time inside a web browser. If you are a developer, you may spend more time inside your editor than in your browser, but you’ll probably still spend a fair amount of time in the web browser. And you are like me, you use Firefox as the browser of choice. If you don’t use Firefox, that’s fine. I’m all about choice. But what I’m about to tell you probably won’t apply to you.
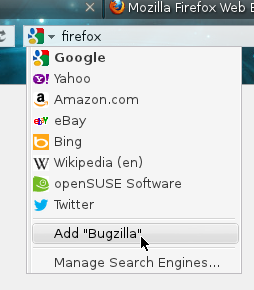
Firefox has an add-on for Bugzilla. It allows you to query Bugzilla directly from its search box at the top-right corner. Installing the extension is also very easy. When you visit your Bugzilla of choice (which in my case the freedesktop bugzilla), click on the icon on the left side of the search box, and click “Add Bugzilla” to add that to the list of your search engines.
You can add multiple bugzilla’s to this list; you just have to follow the same step in each bugzilla you wish to add to your list. For instance, GNOME’s bugzilla gives you “Add GNOME Bugzilla” entry in the same menu.
Get to your bugs fast!
Once you’ve set all these up, getting to the list of bug reports associated with a named tag is very quick. All you have to do is to select Bugzilla as your search engine, type tag:"named tag" in your Firefox’ search box, hit Enter, and you’ll jump right to the list. If your tag includes a space, you’ll need to surround it with double quotes.
Very easy, and very fast. It doesn’t get any better than that.
This is purely a bug fix release, and contain no new functionality since 0.6.0.
This release fixes a bug in the iterator implementation of flat_segment_tree. Prior to this release, the iterator would treat the position immediately before the end position to be the end position, which would result in incorrectly skipping the last data position during iteration. This release contains a fix for that bug.
It also contains fixes for various build errors and compiler warnings.
Many thanks to David Tardon, Stephan Bergmann, Tomáš Chvátal, and Markus Mohrhard for having submitted patches since the release of 0.6.0.
Last week was SUSE Hack Week, where we SUSE engineers were encouraged to be creative and work on whatever project that we had been dying to work on.
Given this opportunity, I decided to try integrating my orcus library project into LibreOffice proper to see how much improvement we could make in the performance of loading spreadsheet documents.
I’ll leave the detailed description and goal of orcus project for another blog post, but in short, orcus is an independent library designed to process spreadsheet documents, and is also designed to be useable from an application that would like to use it to load documents. It’s currently still work in progress, and is not even in alpha quality. So, I intentionally don’t release orcus library packages on an official basis.
Integration work
The main difficulty with integrating orcus into LibreOffice proper was dealing with the very intricate loading process that LibreOffice uses for all existing filters. It first goes through an elaborate type detection process, which loads the content of the file into memory in order for the type detection code to parse it. Once the correct type is determined, LibreOffice then instantiates correct frame loader and start the actual loading process. I’ve explained all of this in detail in this blog post of mine.
Orcus, on the other hand, only needs a file path, and it does the rest. And it pushes data to the call back functions provided by the client code as it parses the file. It was this difference in overall loading process that made the integration of orcus into LibreOffice all the more challenging. And even though the hack week itself lasted only one week, I had spent months prior to it just to study the type detection code and other auxiliary code that makes up the whole file loading process in order to come up with an elegant way to add hook for orcus.
Long story short, I was able to come up with a way to hook orcus such that LibreOffice relinquishes all its file loading to the orcus library, and only handles callbacks. To make this work, I first packaged orcus into an installable rpm package using the openSUSE build service, locally installed that package, then added –with-system-orcus configure option to allow LibreOffice to find the library. The entire change needed to add hook is condensed into this commit.
Using CSV filter as an experiment
As an initial experiment, I replaced the current csv import filter with one from orcus, just to see how this overall process works. The results are very encouraging.
With a very large csv file I created via this python script:
#!/usr/bin/env pythonimportsysfor i inxrange(0,65536):
for j inxrange(1,101):
val = i * 1.0 / j
sys.stdout.write("%g,"%val)sys.stdout.write("end\n")
#!/usr/bin/env python
import sys
for i in xrange(0, 65536):
for j in xrange(1, 101):
val = i * 1.0 / j
sys.stdout.write("%g,"%val)
sys.stdout.write("end\n")
the current filter spends roughly 27 seconds to load this file, which is not too bad given the sheer size of the file (~50Mb). The orcus filter, on the other hand, spends only 11 seconds to load the same file.
However, the orcus filter code path still skips a number of steps that need to be performed if it were to be used in the production build, such as
drawing progress bar in the status bar area,
calculating row heights for rows that include multi-line cell contents, and
probably something else I forget to mention here.
Given some of these can be quite expensive, the above numbers may not be fully comparable. Despite that, these initial numbers show a great promise on the performance improvement that may result from using the orcus library.
Future work
First of all, we will not switch to the orcus csv filter anytime soon. Although I’d like to see that happen at some point in the future, there are still lots of missing pieces in the orcus csv filter that prevent us from using it in the production build. My plan with orcus is therefore limited to addition of new filters, and my immediate plan is to develop new XML import and export filters using orcus, and integrate it into LibreOffice. This should also provide a stepping stone for any additional filters that may come up later, as well as replacing some of the existing filters as the need arises.