Last week was SUSE’s Hack Week – an event my employer does periodically to allow us – hard working engineers – to go wild with our wildest ideas and execute them in one week. Just like what I did at my last Hack Week event, I decided to work on integration of Orcus library into LibreOffice once again, to pick up on what I’d left off from my previous integration work.
Integration bits
Prior to Hack Week, orcus was already partially integrated; it was used to provide the backend functionality for Calc’s XML Source feature, and experimental support for Gnumeric file import. The XML Source side was pretty well integrated, but the normal file import side was only partially integrated. Lots of essential pieces were still missing, the largest of which were
- support for multiple filters from a single external filter provider source (such as orcus),
- progress indicator in the status bar, and
- proper type detection by analyzing file content rather than its extension (which we call “deep detection”).
In short, I was able to complete the first two pieces during Hack Week, while the last item still has yet to be worked on. Aside from this, there are still more minor pieces missing, but perhaps I can work on the remaining bits during the next Hack Week.
Enabling orcus in your build
If you have a recent enough build from the master branch of the LibreOffice repository, you can enable imports via orcus library by
- checking the Enable experimental features box in the Options dialog, and
- setting the environment variable LIBO_USE_ORCUS to YES before launching Calc.
This will overwrite the stock import filters for ODS, XLSX and CSV. At present, orcus only performs file extension based detection rather than content based one, so be mindful of this when you try this on your machine. To go back to the current import filters, simply disable experimental features, or unset the environment variable.
Note that I’ve added this bits to showcase a preview of what orcus can potentially do as a future import filter framework. As such, never use this in production if you want stable file loading experience, or don’t file bugs against this. We are not ready for that yet. Orcus filters are still missing lots and lots of features.
Also note that, while in theory you could enable orcus with the Windows build, the performance of orcus on Windows may not be that impressive; in fact, in some cases slower than the current filters. That is because orcus relies on strtod and strtol system calls to convert string numbers into numeric values, and their implementation depend on the platform. And the performance of MSVC’s strtod implementation is known to be suboptimal compared to those of gcc and clang on Linux. I’m very much aware of this, and will work on addressing this at a later time.
Performance comparison
This is perhaps the most interesting part. I wanted to do a quick performance comparison and see how this orcus filter stands up against the current filter. Given the orcus filter is still only capable of importing raw cell values and not any other features or properties (not even cell formats), I’ve used this test file which only consists of raw text and numeric values in a 8-by-300000 range, to measure the load times that are as fair and representative as I could make them. Here is the result on my machine running openSUSE 11.4:
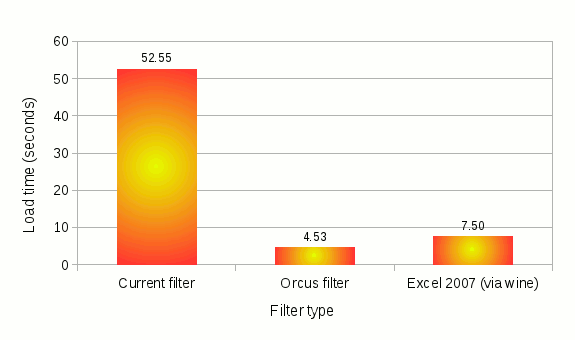
The current filter, which has undergone its set of performance optimizations on raw cell values, still spends upwards of 50 seconds. Given that it used to take minutes to load this file, it’s still an improvement.
The orcus filter, on the other hand, combined with the heavily optimized load handler in Calc core that I put in place during Hack Week, can load the same file in 4.5 seconds. I would say that is pretty impressive.
I also measured the load time on the same file using Excel 2007, on the same machine running on top of wine, and the result was 7.5 seconds. While running an Windows app via wine emulation layer may incur some performance cost, this page suggests that it should not be noticeable, if any. And my own experience of running various versions of Excel via wine backs up that argument. So this number should be fairly representative of Excel’s native performance on the same hardware.
Considering that my ultimate goal with orcus is to beat Excel on performance on loading its own files (or at least not be slower than Excel), I would say we are making good progress toward that goal.
That’s all for today. Thank you, ladies and gentlemen.
For your information: Just tested your sample xsls-file under Ubuntu 12.10:
Excel 2010 (on Codeweaver’s Crossover Office) took 31 seconds to load the file.
LibreOffice 3.6.2.2 took 21 second to load the file.
Do you happen to have Excel 2007 on that machine to test with? I’m wondering whether Excel’s performance got worse from 2007 to 2010. The fact that 3.6.2 loads the same file faster than the master build does is a bit of a surprise, but I can confirm that on my machine too. We may have introduced a new bottleneck somewhere.
Unfortunately, I don’t have Excel 2007 here.
On my machine, the result for Excel 2010 is quite stable also in a second test: 29 seconds vs. 20 seconds in LibreOffice 3.6.2.2. This is just the loading time of the file; the applications were already up and running.
There might be a regression from Excel 2007->2010, but there is also a slight chance that Crossover has some performance problems with Intel SandyBridge chips, which I already had with Powerpoint 2010 presentations.
[…] ottimizzazioni è Kohei Yoshida, sviluppatore SUSE impegnato nello sviluppo di LibreOffice, il quale in un recente test su un foglio elettronico di grandi dimensioni ha ottenuto un netto miglioramento nei tempi […]