Here is another performance improvement that just landed on master.
Background
It was brought to our attention that the performance of saving documents to ODF spreadsheet format had been degrading quite noticeably. This was especially true when the document contained lots of what we call rich text cells. Rich text cells are those cells that contain text with mixed format spans, or text that consists of multiple lines. These cells are handled differently from simple strings internally, and have slightly more overhead than the simple string counterparts. Because of this, saving a document full of such texts was always slower than saving one with just numbers and simple strings.
However, even with this unavoidable overhead, the performance of saving rich text cells was clearly going in the wrong direction. Therefore it was time to act.
Long story short, after many days of code reading and writing, I brought it to a state where I can share some numbers.
Measuring export performance
I measured the performance of exporting rich text cells in the following steps.
- Create a new spreadsheet document.
- Type in cell A1 3 lines of ‘libreoffice’. Here, you can hit Ctrl-Enter to move to the next line within the same cell.
- Copy A1, select A1:N1000 and paste, to replicate the content of A1 to all cells in the range.
- Save the document as ODF spreadsheet document, and measure its duration.
Results
I performed the above measurement with 3.5, 3.6, 4.0, 4.1, and the latest master (slated to become 4.2) builds, and these are the numbers.
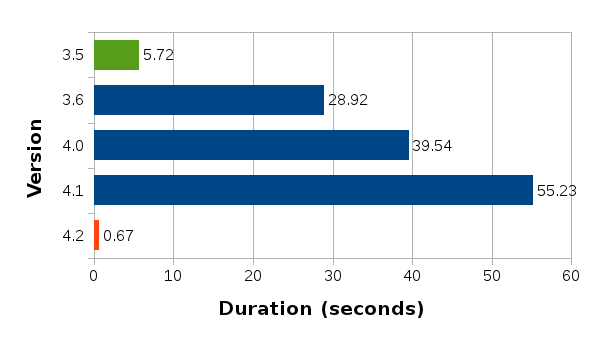
It is clear from this chart that the performance started to suffer first in version 3.6, then gradually worsened over 4.0 and 4.1. The good news is that we have managed to bring the number back down in the master build, even lower than that of 3.5 which I used as the point of reference. Not just slightly lower, but much, much lower.
I don’t know about you, but I’m quite happy with this result.
Great work and thanks!
Improvements in file opening and saving are always great improvements to see.
Personally I always look forward to your improvements since I’m calc user 95% of time. I pretty much suck at impress. :)
Thanks a lot for your encouraging words! Performance is one area I just can’t turn my back on. So I’m really glad to have finally taken care of this long standing issue.
Tested your test on 4.0 and it took 74 seconds on my little bit older PC (without any other task on PC running at the same time – checked Windows Task Manager). So you got to run this test on some recent computer. Could you write some PC specifications you run tests on.
“Tested your test on 4.0 and it took 74 seconds” – the improvements are in LibO4.2 (so called “master” at the moment, sometimes alled “nightlies”)
Yes, I know this… I just looked at the graph v4.0 were is 39 seconds and compared to my v4.0 were is 74. So I am comparing the same version of software, so wondering what was the PC the test were run on.
I use a machine with quad core Intel Xeon clocked at 2.53GHz, with 12 GB of RAM. No SSD, just a conventional spinning hard drive.
Looks as if we need to prepare a warning : ‘yes, that was fast, but your spreadsheet has really been saved’ or similar ;)
Thanks a lot, Kohei.
Well done on this and other calc performance work, its appreciated
Thank you for the great work. I just got bitten by this bug today and am happy I could download a nighty. On OS X, there is a significant improvement with the nighty. Save times went down from around 10 to only 2 minutes.
The first 85% of the progress bar is completed withing a second but then the last part still takes minutes.
If you are interested, I could share with you my data. It is semi-confidential and as it contains email addresses I do not want to disclose it on any public forum.
File size: ~300K
1 sheet, 1910 rowns and 26 columns. No formulas. (Yes, I should have used a DB instead)
It would be great if you could somehow anonymize your document and file a bugzilla report. If it’s just email addresses, it should be possible to scramble them somehow.
The easiest way is to use Find & Replace and just changing one letter by one letter.
E.g. change a for x, i for w, o for f etc. Doing this multiple times and mails will look masked.
Just don’t disclose the algorithm you have used, because of possible reverse engineering.
Then report bug at: https://www.libreoffice.org/get-help/bug/
Great! Also what a nice blog. Didn’t know this existed. Wish, LO was more able to present itself in a similar nice fashion. But it still comes with Times New Roman as default font… :P
I also don’t like Times New Roman as default. I have to change this font to Arial where ever possible. Special don’t really understand why this font is default inside tables, obviously difficult to read data with this font…
… But this was not the topic of this blog post.
Would you share some details about how you did this? Bad algorithm? Memory issues? Thanks!
I would say both. The algorithm was not optimal, plus it was doing too many memory allocations and deallocations that were entirely unnecessary. The whole design of the code in question was not architected with performance in mind.
I guess the same holds true for #fdo30770?
[…] lo stesso ingegnere del software e sviluppatore di spicco del progetto ad annunciare di aver corretto una brutta regressione che ha colpito varie release del programma. Il bug […]
Windows 8.1 / Office 2013 user here. I keep a tab on open-source software because change may be coming. Also, I often install LO on family and friends’ computers. I read the release notes for version 4.2 and wanted to thank you for your many contributions. Thanks to you, and all the other volunteers, LO is making strides! Keep it up!